…..
上面这个示例有些不能完整体现,另外一个例子是
原输入数据为:A B A B A B A B B B A B A B A A C D A C D A D C A B A A A B A B ….. 采用LZW算法对其进行压缩,压缩过程用一个表来表述为:
注意原数据中只包含4个character,A,B,C,D
用两bit即可表述,根据lzw算法,首先扩展一位变为3为,Clear=2的2次方+1=4; End=4+1=5;
初始标号集因该为
0
1
2
3
4
5
A
B
C
D
Clear
End
而压缩过程为:
第几步
前缀
后缀
Entry
认识(Y/N)
输出
标号
1
A
(,A)
2
A
B
(A,B)
N
A
6
3
B
A
(B,A)
N
B
7
4
A
B
(A,B)
Y
5
6
A
(6,A)
N
6
8
6
A
B
(A,B)
Y
7
6
A
(6,A)
Y
8
8
B
(8,B)
N
8
9
9
B
B
(B,B)
N
B
10
10
B
B
(B,B)
Y
11
10
A
(10,A)
N
10
11
12
A
B
(A,B)
Y
…..
当进行到第12步的时候,标号集应该为
0
1
2
3
4
5
6
7
8
9
10
11
A
B
C
D
Clear
End
AB
BA
6A
8B
BB
10A
8.LZW算法的伪代码实现
1STRING =get input character 2WHILE there are still input characters DO 3 CHARACTER =get input character 4 IF STRING+CHARACTER isin the string table then 5 STRING = STRING+character 6 ELSE 7 output the code for STRING 8 add STRING+CHARACTER to the string table 9 STRING = CHARACTER 10 END of IF 11END of WHILE 12output the code for STRING 13
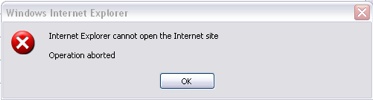
How to Fix “Internet Explorer Cannot Open the Internet Site- Operation Aborted” Error
Of late few of my blog readers using Internet explorer pointed out to me that there was some error happening while loading my blog in IE. Around 25% of my readers use Internet Explorer to read my blog. I check my blog frequently in IE and many times I too encountered this error, but initially I thought it was some error in my browser. The error is really frustrating as it shows only in IE and not in Firefox or Opera or any other browser for that matter.
The nature of error is that it shows up when the site is loads completely. This is what you see when the error occurs.
Once you click OK, the page is replaced with “The Page cannot be Displayed” error. How to fix this error?
A bit of Googling gave me some idea into this error. This error can happen because of many reasons. Microsoft has even a patch for solving this error in IE.
1. This error can happen if Google Map API is present in the code. If you are getting this error because of Google Map API, then the fix for the problem is available here.
2. If you are not using Google API and still getting the error, then it could be because of this reason.
It is not possible append to the BODY element from script that isn’t a direct child to the BODY element
If there are any Javascripts running inside the body tag or inside a table which is directly a child of body, then most of the times this error is bound to happen. The solution is to move the script to the top or bottom of the body tag or even moving it after the body. The script can also be put inside a function and then calling it from window.onload. Another solution to this problem is to add defer=”defer” in the script tag.
I checked my code for scripts which were running inside the body tag and was a direct child to it. Then I moved all my Javascript codes to bottom of the body tag so that it will not interfere while parsing the page. I tested my blog in IE after I made the change and I could see the difference, the error was not happening any more. I checked in different versions of IE to confirm. In case you are using IE and still getting the error on my blog, please do inform me.
<div class="left">div left float:none</div>
<div class="right">div right [www.52css.ocm]</div>
<div class="leftfloat">div left float:left</div>
<div class="right">div right [www.52css.ocm]</div>
<span class="left">span left float:none</span>
<span class="right">span right</span>
这里所说的 XMLReader API 位于 Gnome Project 中用于 C 和 C++ 的 libxml 库之上。实际上 XMLReader 只是在 libxml 的 XmlTextReader API 之上的很薄的 PHP 层。XmlTextReader 本身是模仿 .NET 的 XmlTextReader 类和 XmlReader 类,尽管并不具有与这些类相似的代码。
与 Simple API for XML (SAX) 不同,XMLReader 是推解析器,而不是拉解析器。这意味着程序是可以控制的。您将告诉解析器何时获取下一个文档片段,而不是在解析器看到文档后告诉您所看到的内容。您将请求内容,而不是对内容进行反应。从另一个角度来考虑这个问题:XMLReader 是 Iterator 设计模式的实现,而不是 Observer 设计模式的实现。
<br /> <b>Warning</b>: XMLReader::read() [<a href='function.read'>function.read</a>]: < value><double>10</double></value> in <b>/var/www/root.php</b> on line <b>35</b><br />
您可能不希望将它复制到用户所看到的 HTML 页面中。更好的方法是在 $php_errormsg 环境变量中捕获错误消息。为此,需要启用 php.ini 文件中的 track_errors 配置选项:
track_errors = On
默认情况下,track_errors 选项是关闭的;这在 php.ini 中是显式指定的,因此请确保更改了该行代码。如果提早在 php.ini 中添加了上述一行代码(正如最初我所进行的操作),则后面的 track_errors = Off 代码将重写先前的代码。
// set up the request $request = $HTTP_RAW_POST_DATA; error_reporting(E_ERROR | E_WARNING | E_PARSE); if (isset($php_errormsg)) unset(($php_errormsg); // create the reader $reader = new XMLReader(); // $reader->setRelaxNGSchema("request.rng"); $reader->XML($request);
$input = ""; while ($reader->read()) { if ($reader->name == "double" && $reader->nodeType == XMLReader::ELEMENT) {
// make sure the input was well-formed if (isset($php_errormsg) ) fault(21, $php_errormsg); else if ($input < 0) fault(20, "Cannot take square root of negative number"); else respond($input);
这是 XML 流处理中简单的常见模式。解析器将填写一个数据结构,当完成文档时该数据结构将起作用。通常数据结构要比文档本身简单。这里所使用的数据结构尤其简单:一个字符串。
if (!isset($HTTP_RAW_POST_DATA)) { fault(22, "Please make sure always_populate_raw_post_data = On in php.ini"); } else {
// set up the request $request = $HTTP_RAW_POST_DATA; error_reporting(E_ERROR | E_WARNING | E_PARSE); // create the reader $reader = new XMLReader(); $reader->setRelaxNGSchema("request.rng"); $reader->XML($request);
$input = ""; while ($reader->read()) { if ($reader->name == "double" && $reader->nodeType == XMLReader::ELEMENT) {
* 使用 RELAX NG 反击,第 1 部分(David Mertz,developerWorks,2003 年 2 月):使用 RELAX NG 来创建强大的、简练的、语义简单易懂的类,用于描述有效 XML 实例。
* Design Patterns(Addison-Wesley,1995 年):深入研究 Gang of Four 的力作中对 Observer 和 Iterator 设计模式的阐述。
* IBM XML 认证:了解如何才能成为一名 IBM 认证的 XML 及相关技术的开发人员。
* XML 技术库:查看 developerWorks 中国网站 XML 专区,获得大量技术文章、技巧、教程、标准以及 IBM 红皮书。
* developerWorks 技术活动和网络广播:随时关注这些会议中的技术进展。
获得产品和技术
* 使用 IBM 试用版软件:构建您的下一个开发项目,可直接从 developerWorks 下载。
讨论
* XML 专区讨论论坛:参与任何一个面向 XML 的论坛。
* 通过参与 developerWorks blogs 加入 developerWorks 社区。
关于作者
Photo of Elliot Rusty Harold
Elliotte Harold 出生在新奥尔良,现在他还定期回老家喝一碗美味的秋葵汤。但目前他和妻子 Beth、他们的狗 Shayna、猫 Charm 和 Marjorie 定居在布鲁克林附近的 Prospect Heights。他是 Polytechnic 大学的计算机科学副教授,讲授 Java 和面向对象编程。他的 Cafe au Lait Web 站点是 Internet 上最受欢迎的独立 Java 站点之一,子站点 Cafe con Leche 是最受欢迎的 XML 站点之一。他的著作包括 Effective XML、 Processing XML with Java、 Java Network Programming 和 The XML 1.1 Bible。他的最新著作是 Java I/O, 第二版。他目前从事 XOM API 处理 XML、Jaxen XPath 引擎和 Jester 测试覆盖工具的研究。
 STRING = get input character
STRING = get input character
 Example Source Code
Example Source Code  Source Code to Run
Source Code to Run